Midterm Status
Our class is half over and it is time for our midterm full-class feedback session. I've made a lot of progress recently and am excited to share my work with my fellow students. I will definitely achieve my original goals for this class, however, if that's the only thing I do with this, it would be a crime. This project is absolutely going to live on long after this class is over.
Image Stitching
In my last post I wrote about an an image stitching problem that I was struggling with. I thought this was an abnormality or shortcoming in the data that I was going to have to live with. It was irritating but manageable for the images near NYU I was testing my code with, but when I started downloading more data for other locations I found the issue could be much more severe. I was frustrated because it was undermining what I wanted to do with the data.
I did research into image stitching and discovered that the issue was caused by camera tilt. When Google is driving their Street View car around town the camera is never perfectly level with the ground. It makes sense that this would be the case, but apparently the processed data I am querying using Google's Street View Image API does not correct for this. Curiously they use machine learning to remove the car itself from the images but they don't correct for camera tilt. I did some investigation and discovered this is also the case when we use Google Maps. The data is served to your browser with tilted photos but is corrected on the client side before you see it.
The camera tilt problem is much more severe when the Street View images are captured by a hiker with a backpack mounted camera. If that person trips over a rock or branch when it takes a photo, that's the photo you get. The most unique pictures Google Street View offers are taken using this method so it was important to me that I fix this.
Happily I came up with a clever fix for this that doesn't involve content-based image stitching. It took a few weeks for me to figure this out but I got it. I won't go into any details here but I was absolutely thrilled when I figured it out.
Map Crawler
The core part of my data acquisition strategy is a map crawler that navigates Google's data the same way a web crawler navigates the web. I wanted my code to be efficient and guarantee to not ever request the same data twice.
Below is a graph of the locations I have data for near ITP. Linked locations are represented with lines connecting them.
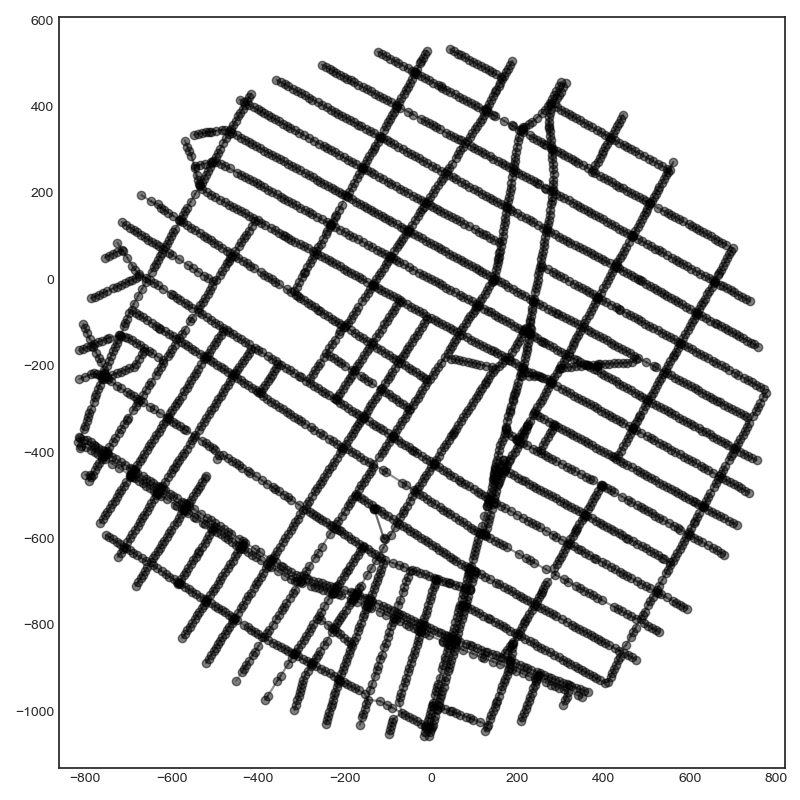
That is a matplotlib figure I put together for a simple UI. With the amount of data I plan to download I needed to build tools to visualize what I have and organize it in some way. I used matplotlib's event handlers to give me the ability to zoom in and out or mark locations. I can click on locations and it will automatically show me the picture for that location. This is what I get when I click on Broadway outside ITP:

That is an equirectangular projection, the format typically used for panoramas. I am not limited to this format but find it to be convenient for data exploration purposes.
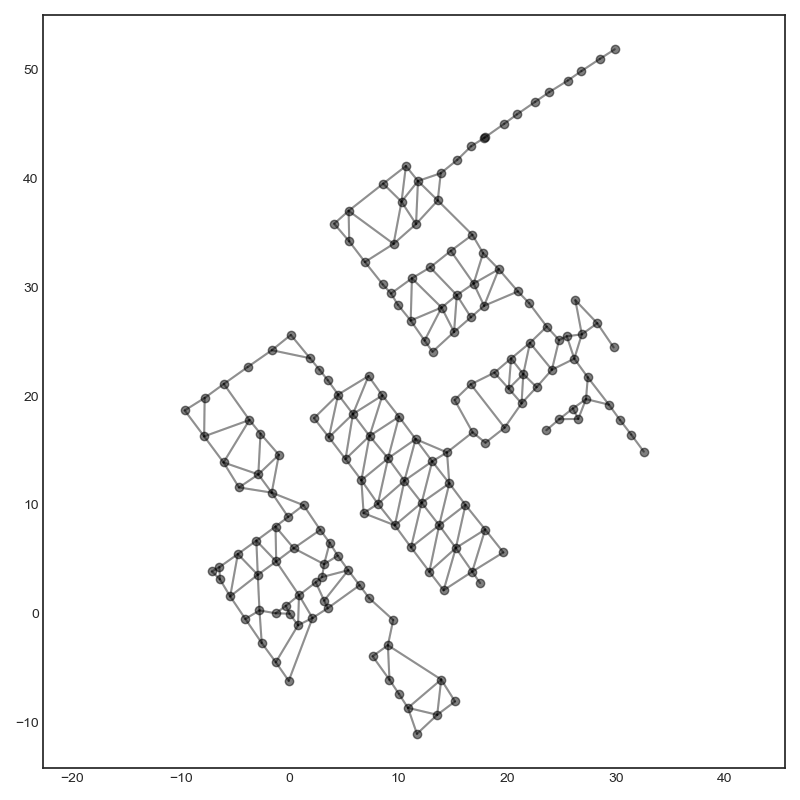
Google Street View spans the globe. Here is a graph of the data for inside the Noordeinde Palace in The Hague, Netherlands.
And a picture from inside:

Using Google Maps I can identify interesting locations to query. I wanted a place in the Middle East and found a hiking trail in Israel:
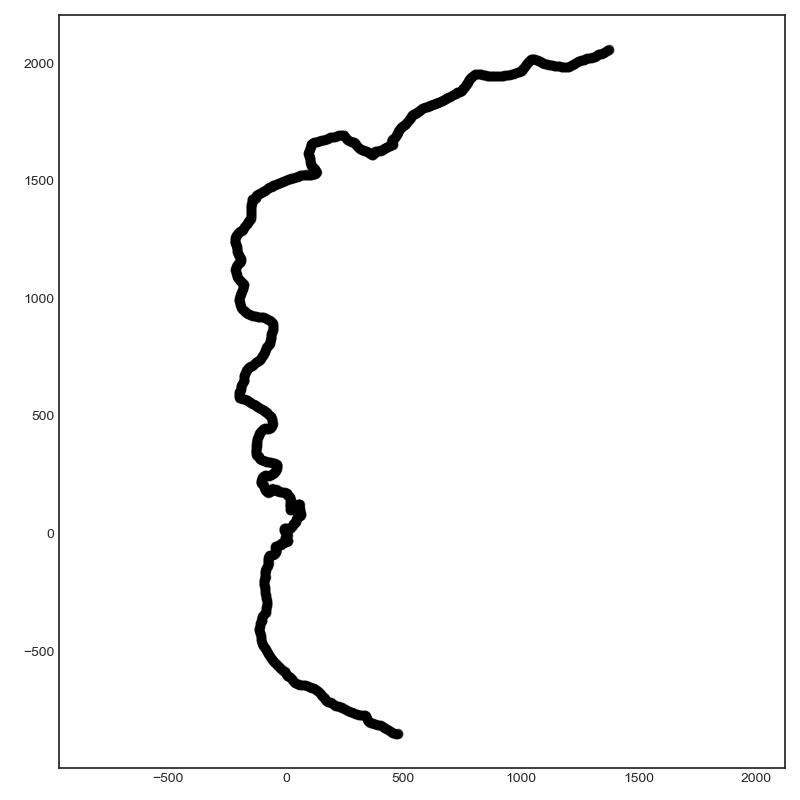
You can see from the shadow below that an adventurous soul hiked through the desert wearing a backpack mounted camera. I can also see from the data that they walked slowly...I have much respect for their efforts.

I have a constantly growing spreadsheet of interesting locations I'd like to download data for. The potential of what I can accomplish with this tool is vast.
Enhanced Photography
I started this project because I was interested in machine learning and computer graphics. It is clear to me that I can go in a lot of directions here, but the direction that interests me the most right now is using neural networks to enhance the pictures.
The thing with Google Street View pictures is that they are often dull to look at. Google is collecting many pictures every day and they don't have the time to sit at one location and take the perfect shot like a photographer would. If the Street View car drives past a beautiful lake on a cloudy and overcast day, that's the picture we get to look at. Can I use computers to enhance the pictures and make them more interesting?
Here is a photo of a dock near Lake Rotoiti, New Zealand.

Here is the same photo with a style transfer applied:

I think it looks better. Not bad for a first attempt at this.
I am using an open source library created by Cameron Smith. Over the next few weeks I am going to experiment with these kinds of tools and will eventually build my own.
Here is a photo of US-12 in Idaho:

And the same photo with a style transfer:

I am quite pleased with how this came out. The trees have visible brush strokes and the top of the mountain is sun-kissed.
Single-frame pictures is one thing. How about videos?
With my code I can also export a series of pictures from one region in the proper order. The pictures can then be assembled into a movie, like so:
Later I will make some improvements to smooth out the camera motion.
There's also a 360 Video version:
This might not be a typical use of 360 video but I certainly enjoyed that a lot.
Here is the same video but with a style transfer applied to each frame. This video uses an optical flow algorithm to identify moving objects from frame to frame. This allows for the creation of coherent videos with consistent styles applied to objects. Coherency reduces the flickering that typically occurs in these kinds of videos.
This is only 5 seconds because it takes a long time to create.
Many Directions
As far as form goes there are two other directions I can go here other than single frame images and videos. Two that I can think of right now, that is.
I can use the data to make compositions. Using the depth data for each location I can build a crude 3D world that I can insert rendered objects into. For example, I can model a car and add it to the video. I am not going to pursue this now as it will take too much time. I have not yet parsed the depth data, and when I do parse it, I know it will be more work to figure out the math for how to use it properly. I will do this eventually but not now. After I learn more about 3D modeling programs like Blender or Cinema4D I will pursue this.
Videos are based on a sequential series of pictures. There is no reason I need to limit myself to a linear structure. There are other interactive approaches that could link the panoramas together into a network of some kind.
There is also much to learn about machine learning. I very much want to delve into the programming aspect of this. I'm not going to use someone else's code to do style transfers. I should be doing that myself. I also want to move from style transfers to style generation. I have some ideas but I need to know more about deep learning to try them out.
No matter what I am going to have to leverage cloud computing to complete this project. Luckily I have a lot of free credits for GCP and AWS that will expire soon. I am happy to use them for this project.
Style transfers for 360 video is not an area of deep learning research that has been well explored. Based on my experience with this kind of imagery I have some ideas I'd like to try.
I could apply object detection and instance segmentation algorithms to these images. I can also create masks to use as an input to a style transfer algorithm.
Another dimension I could explore is marrying this dataset with other datasets. The sky's the limit.
Outside of technology there are many directions I can pursue. There are lots of interesting places to visit with Google Street View. Beautiful or ugly, this is our world. I found several subreddits specifically devoted to Google Street View finds. People put a lot of effort into exploring Google Street View. I have been going through the subreddits and found things I never would have thought of on my own. It would be interesting to juxtapose the palace pictured above with this trash pile or this tree. I'm looking forward to discussing this with the class when I present my progress.
Next Steps
I'm so excited with how well this project is going I am feeling overwhelmed. There is a lot I can do here and there is no way I will accomplish all of it by the end of this class. But that's OK! That's more than OK! So much to learn! I wouldn't have it any other way. I signed up for this class because I wanted to learn more about computer graphics and machine learning and that's what's going to happen. There is plenty for me to do here.
For the purpose of this class I do need to make some decisions about what to do. I need to pick something that I can accomplish by the end of the semester. The end of the semester will not be the end of my work here.
In the short term I will continue to explore and experiment with the data. I will read research papers and start coding my own style transfer algorithms. I know there are things in this data waiting to be discovered. I don't want to impose my own ideas; the most interesting ideas people will care about the most will come from the data itself. Discovering them will be what makes my work here significant. This will take time, but I know the only way to get there is to dive into the data and immerse myself in it. And that's what I am going to do.
Comments