Great Heart Physical Computing Project
Team
The Great Heart project is the result of the hard work and effort of Camilla Padgitt-Coles and James Schmitz.
Project Summary
"Great Heart" is a collaborative project created for Tom Igoe’s Introduction to Physical Computing class by Jim Schmitz and Camilla Padgitt-Coles. The project uses a pulse sensor to detect the user's heartbeat and translate it into sound. The user can hear their heart rate sonified and follow breathing visualizations which are designed to guide their breathing to help users achieve inner peace, release anxiety, and slow their heart rate down. The user puts on a wristband with the pulse sensor attached and sits as long as they choose with the sounds and visuals.
Using push buttons on the device’s enclosure, the user is invited by the audio guide on the Introduction screen to choose from different instruments and notes to represent their heartbeat. Their heart rate is also represented as a pulsing light on the enclosure and as a pulsing light next to the breathing exercises in P5. After the meditation has finished, the user is told what their beginning and ending heart rates were.
There are two options: A "challenge" mode where the program stops once your heart rate has slowed by 10%, and a "meditation" mode where the user can sit and breathe for a fixed or variable duration (for the winter show we chose a 2 minute duration).
The project is modular and allows the freedom to change the audio and visual aspects and various components of the program in P5 as needed. The Arduino sends the heart rate data and button-press messages for the instrument, note and sustain on/off buttons through serial communication to P5. The rest is coded in P5 using JavaScript, audio samples, and images.
System Diagram
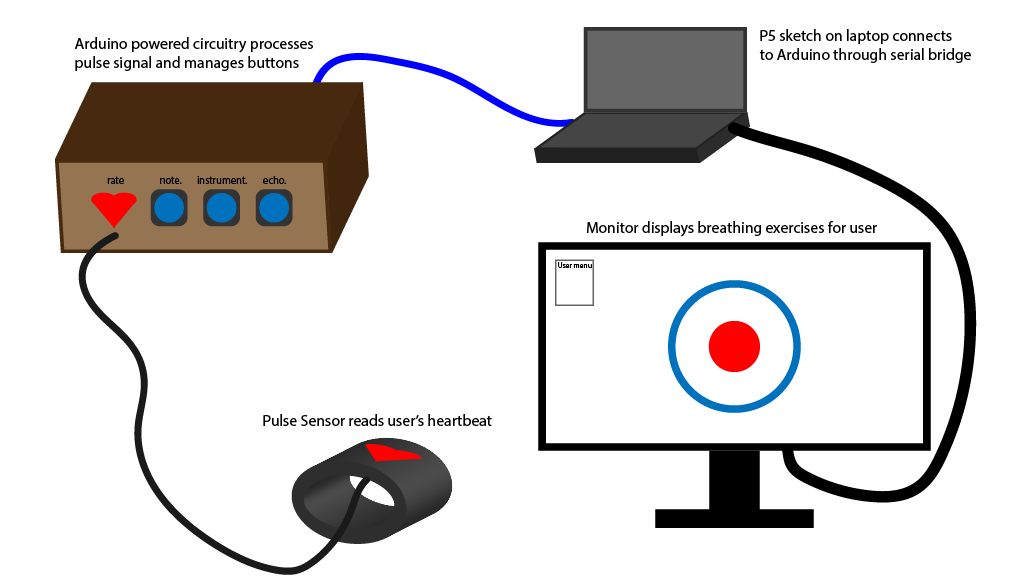
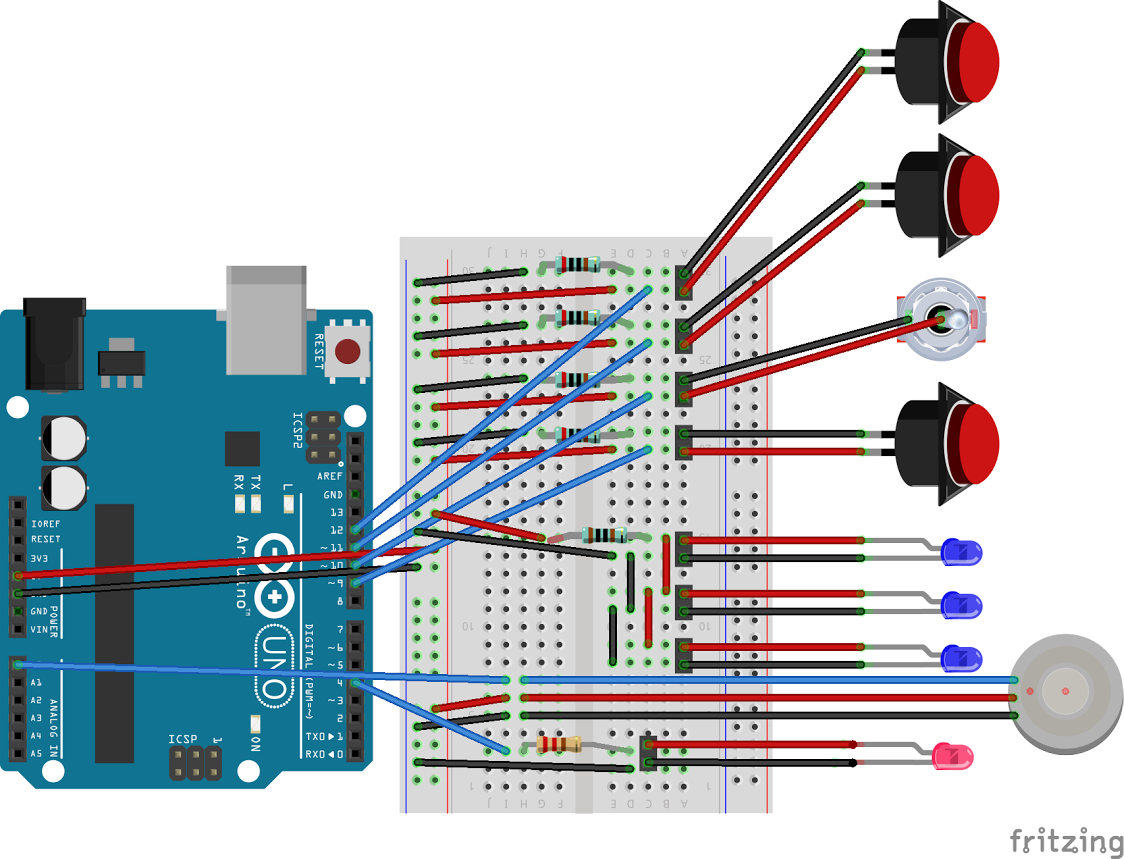
Fritzing Diagram
Next Steps
Camilla and I are going to continue working this project over the winter break. We will create another enclosure identical to the one we use in the show. We will also make a high quality video documenting the project. And finally, we will finalize the algorithm changes to the Pulse Sensor library to contribute back to the Arduino Pulse Sensor library repository.
Comments